Il marketing B2B che ha smesso di sapere chi ha scritto cosa
C’è un punto a cui sono arrivati molti team marketing B2B negli ultimi diciotto mesi: non sanno più, con precisione,
Il cambiamento è andato più veloce dei processi interni, non certo un male una volta tanto ma qualcosa sdi cui prendere consapevolezza.
Una persona ha generato un’immagine con Midjourney per un carosello, qualcun’altra ha riscritto un blog post con ChatGPT, una marketing manager ha usato Claude per la sintesi di un report di settore. Ogni passaggio è razionale. Manca solo la traccia, una traccia che è diventata importante.
Il 10 giugno 2026 la Commissione Europea ha pubblicato il Code of Practice finale su marcatura e labeling dei contenuti AI-generati: un vademecum operativo che accompagna l’Articolo 50 dell’EU AI Act, in vigore dal 2 agosto 2026. Un cambio di assetto documentale che ha senso preparare adesso, senza poi farsi prendere dalla fretta.
Cosa impone esattamente l’Articolo 50
L’Articolo 50 dice due cose nette:
- chi sviluppa sistemi AI generativi deve marcare in formato machine-readable gli output del proprio sistema.
- chi utilizza quei sistemi in modo professionale per produrre contenuti pubblici deve etichettare chiaramente i deepfake (audio, video, immagini) e i testi AI-generati o AI-manipolati pubblicati su questioni di interesse pubblico.
Il perimetro di “interesse pubblico” è ampio. Include posizioni su trend di mercato, politica industriale, salute pubblica, sicurezza, energia, decisioni di policy. Per un marketing B2B che pubblica position paper, contenuti d’opinione, o anche solo caroselli LinkedIn su evoluzioni di settore, gran parte di quanto viene prodotto rientra nel perimetro.
Il Code of Practice pubblicato il 10 giugno è volontario, chi lo firma documenta la compliance con un meccanismo standard, chi non lo firma dovrà dimostrarla con altri mezzi alle autorità di vigilanza nazionali. Il documento è stato sviluppato dalla Commissione tramite l’European AI Office con oltre 187 partecipanti tra industria, accademia, società civile, titolari di diritti e Stati membri dell’AI Board.
Perché firmare il Code conviene anche a chi non è Google o Adobe
Firmare è volontario, ma non è una scelta neutra. La Commissione ha previsto un meccanismo preciso: chi firma e implementa le misure beneficia di una presunzione di conformità rispetto agli obblighi dell’Articolo 50. In pratica, l’enforcement futuro delle autorità di vigilanza, sui firmatari, sarà focalizzato sul monitoraggio dell’adesione al Code, e non sull’accertamento ex novo della compliance.
Per un’azienda B2B questo si traduce in quattro vantaggi concreti, indicati esplicitamente dalle FAQ ufficiali dell’AI Office:
▪️ Certezza giuridica omogenea in tutta l’UE, indipendentemente dal Paese in cui l’azienda opera.
▪️ Riduzione del carico amministrativo rispetto a chi dovrà dimostrare la compliance “con altri mezzi”.
▪️ Framework di marcatura riconosciuto, che riduce il rischio di scegliere approcci tecnici che poi non vengono ritenuti sufficienti dalle autorità.
▪️ Trust signaling verso clienti, partner e investitori. Comparire nell’elenco pubblico dei firmatari accanto ai grandi vendor AI è un segnale di mercato a costo marginale.
Firmare non è obbligatorio. È la corsia preferenziale per dimostrare compliance. Per un’organizzazione che produce contenuti pubblici con AI generativa, restare fuori vuol dire scegliere consapevolmente la corsia con più traffico.
Tre modi di marcare un contenuto, e quando usarli
Il Code identifica due meccanismi tecnici principali per marcare i contenuti, più un terzo opzionale (fingerprinting). La domanda operativa, per chi non scrive software, è: come si traducono in pratica?
Esistono tre livelli di marcatura, con soglie di accessibilità diverse.
Disclosure testuale: la base accessibile a chiunque
Aggiungere una nota chiara su ogni contenuto pubblico: “Contenuto creato con il supporto di [tool], rivisto e validato da [persona o team]”. Su un PDF, alla fine di un articolo, in un piè di pagina, nelle note di un carosello LinkedIn. Non richiede competenze tecniche, costa zero, facile e veloce, e per la maggior parte dei contenuti B2B di un’azienda è sufficiente come baseline di trasparenza.
Il limite è che la disclosure testuale è facilmente removibile con un copia-incolla e non viaggia col file. Per i contenuti che attraversano piattaforme (un’immagine ricondivisa, un video tagliato, un report convertito da PDF a slide), serve qualcosa di più robusto. Ma quello diventa un problema di copyright.
Content Credentials (standard C2PA): il livello cresciuto del mercato
C2PA è uno standard aperto sviluppato da una coalizione che include Adobe, Microsoft, Intel, BBC, Truepic. Funziona come un’etichetta nutrizionale crittografata per i file: metadata firmati digitalmente che registrano origine, strumenti usati, modifiche subite. I metadata viaggiano col contenuto, sopravvivono all’editing in tool compatibili, e sono verificabili da chiunque tramite portali pubblici come verify.contentauthenticity.org.
Cosa significa in pratica per un team marketing B2B:
- I file immagine esportati da Photoshop, Lightroom e Firefly embeddano Content Credentials automaticamente da circa due anni, se l’opzione è attiva nei settings.
- DALL-E 3 di OpenAI, sia dentro ChatGPT sia via API, embedda Content Credentials nativamente.
- LinkedIn ha integrato la visualizzazione dell’icona Content Credentials: chi pubblica un’immagine credentialed la vede mostrata automaticamente come AI-generated nel feed.
- Cloudflare preserva i Content Credentials anche dopo le trasformazioni di immagine.
Per un team che produce immagini con tool Adobe o OpenAI, attivare i Content Credentials è una scelta di impostazione, non un progetto. La complicanza emerge quando il flusso passa da un tool credential-aware a uno che rimuove i metadata. Qui serve un audit del workflow.
SynthID: il watermark invisibile di Google DeepMind
SynthID è un watermark embedded direttamente nei pixel (per immagini e video), nello spettrogramma (per audio), o nella distribuzione probabilistica dei token (per testo generato). È nativo nei tool generativi Google: Gemini per il testo, Imagen per le immagini, Lyria per l’audio, Veo per il video.
Il watermark sopravvive a cropping, compressione, filtri leggeri, ed è verificabile tramite il SynthID Detector. Per volume è oggi la soluzione di marcatura più estesa al mondo: Google dichiarava oltre dieci miliardi di contenuti watermarked già nel 2025.
Limite importante per chi lavora prevalentemente su testo: il watermark SynthID Text resiste a paraphrasing leggero, ma può essere indebolito da riscritture massicce o traduzioni. Un blog post tradotto integralmente dall’inglese all’italiano partendo da un draft di Gemini potrebbe non essere più rilevabile come AI-generated.
Le icone EU: una grammatica visiva pronta all’uso
Insieme al Code, la Commissione ha pubblicato una serie di icone standardizzate che chiunque può usare liberamente per etichettare i contenuti AI-generated. Sono tre, ciascuna in quattro varianti grafiche (nera, bianca, e le rispettive versioni al 50% di trasparenza), disponibili in PNG e SVG sul sito ufficiale, senza obbligo di attribuzione.
Le tre icone coprono i tre scenari principali:
▪️ Deepfake creato con AI, per immagini, audio o video che assomigliano a persone, luoghi o eventi reali.
▪️ Contenuto generato interamente da AI, senza intervento umano significativo.
▪️ Contenuto parzialmente modificato da AI, per asset originariamente umani su cui sono stati applicati ritocchi o alterazioni generative.
Le regole di placement che il Code suggerisce sono semplici e ragionevoli: l’icona deve essere percepibile al primo contatto con il contenuto, embedded direttamente nel file o nel testo pubblicato, e deve restare visibile anche dopo download o ricondivisione. Va accompagnata da una breve nota testuale in linguaggio chiaro, perché l’icona da sola raramente è autoesplicativa al primo incontro.
Per un team marketing B2B, il vantaggio operativo è doppio. Primo: non serve disegnare un’icona aziendale, c’è già uno standard visivo riconoscibile. Secondo: l’omogeneità tra brand riduce il “rumore” della trasparenza. Quando tre concorrenti, un cliente e un fornitore usano la stessa icona, il pubblico smette di chiedersi cosa significhi e inizia a leggerla come informazione di base, come si fa con il simbolo del riciclo o con il marchio CE.
Le icone si trovano sul sito ufficiale della Commissione, nella pagina dedicata. I non firmatari del Code possono usarle, ma con un caveat importante: l’utilizzo non costituisce automaticamente un’adesione al Code, e non va presentato come tale.
La parte che non è tecnica, e che pesa di più
Il Code of Practice si concentra sui meccanismi tecnici. Quello che il Code non risolve, e che resta in capo a chi guida un team marketing, è l’assetto documentale interno. Dall’osservazione del fenomeno, è qui che molti team perderanno più tempo, perché è la parte invisibile della trasparenza.
Tre elementi pratici da costruire prima del 2 agosto.
Un registro interno dei contenuti pubblicati con componente AI. Foglio di calcolo o database, è una scelta organizzativa. Cosa traccia: titolo del contenuto, data di pubblicazione, percentuale stimata di AI-generated, tool utilizzati, nome della persona che ha firmato la versione finale. Non serve essere perfetti: serve avere una traccia ricostruibile a posteriori.

Una catena di firma chiara. Chi firma cosa, e che cosa significa firmare. Per un carosello LinkedIn AI-generated rivisto da una marketing manager prima della pubblicazione, la firma riconosce due cose insieme: che il contenuto è stato prodotto in parte con AI, e che una persona è responsabile dell’output finale. Senza questa catena chiara, la disclosure testuale diventa una formula vuota.
Un audit del workflow. Quali tool oggi in uso preservano i Content Credentials, e quali li eliminano? È una domanda che nessun team marketing B2B si è mai posto, e che dal 3 agosto inizierà a contare. Un audit di mezza giornata, fatto adesso, evita di scoprirlo a posteriori.
Cosa fare adesso, in pratica
Non è una corsa contro l’orologio. Sono cinquanta giorni, e le scelte sensate vanno fatte con calma. Tre passi concreti per un team marketing B2B, in ordine di priorità.
- Mappare cosa si pubblica ogni settimana, distinguendo contenuti puramente umani, contenuti AI-assistiti rivisti da persone, contenuti AI-generated con minimo intervento umano. È la base senza la quale ogni discussione su marking diventa accademica.
- Iniziare da subito con la disclosure testuale standardizzata: una formula uguale per tutti i contenuti AI-assisted, applicata coerentemente. È il livello minimo, e basta per buona parte dei contenuti B2B.
- Attivare i Content Credentials nei tool dove già esistono: Adobe, OpenAI via DALL-E, e i prossimi che si stanno integrando. Costo zero, beneficio incrementale.
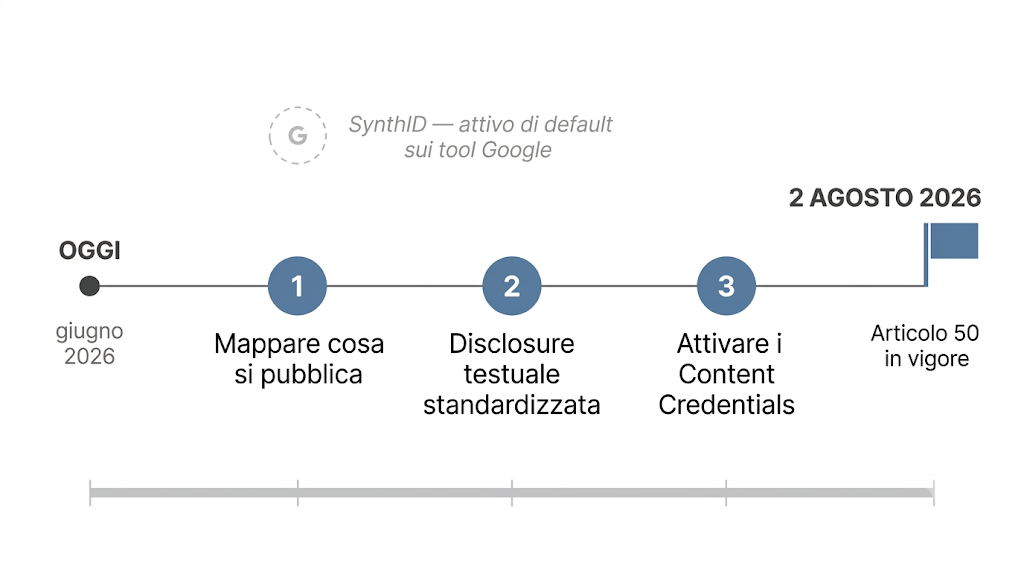
Per i contenuti generati con tool Google, SynthID è già attivo di default e non richiede interventi.
Dal 2 agosto si pubblica come prima. Cambia cosa va documentato, e con quale traccia. La trasparenza dell’AI, vista da dentro, è prima di tutto un assetto interno chiaro.
Fonti
Commissione Europea, Code of Practice on Transparency of AI-Generated Content, press release, 10 giugno 2026.
Come firmare il codice di buone pratiche sulla trasparenza dei contenuti generati dall’IA https://digital-strategy.ec.europa.eu/it/library/how-sign-code-practice-transparency-ai-generated-content
European AI Office, FAQ ufficiale sul Code of Practice.
C2PA / Coalition for Content Provenance and Authenticity, sito ufficiale.
Content Credentials https://contentcredentials.org/
Content Authenticity Initiative (Adobe), How it works.
Adobe Experience League, Content Credentials integration in GenStudio for Performance Marketing.
IPTC, European AI Office releases Code of Practice on Transparency of AI-Generated Content, 10 giugno 2026.
Google DeepMind, SynthID.
Google DeepMind, Watermarking AI-generated text and video with SynthID.
NOTA: cominciamo da subito con le buone pratiche. Questo contenuto è stato creato con il supporto di Claude Opus 4.7, rivisto e validato da Ester Liquori. Le immagini sono state create con il supporto di Gemini.